Introduction
The SOEST Scholars program is an undergraduate research program at the School of Ocean and Earth Science and Technology (SOEST) at the University of Hawai‘i (UH) that runs throughout the academic year. Like many undergraduate research programs, it includes closely mentored research experiences, professional development training, and cohort-building activities. Originally developed by the Center for Microbial Oceanography: Research and Education (C-MORE) to train students in biological oceanography, the program later evolved into the SOEST Scholars Program in 2016 and now spans a wider variety of disciplines, including chemical and physical oceanography, Earth science, and environmental science.
There is a continuing lack of diversity in the field of oceanography. Although the number of PhDs awarded in oceanography has risen sharply in the last decade, those awarded to ethnic and racial minorities have remained stagnant (Bernard and Cooperdock, 2018). Thus, one of our key program goals is to broaden participation among students from groups that have been traditionally underrepresented in STEM, including women, indigenous students, and other ethnic and racial minorities. Toward this goal, we established recruiting partnerships with various Native Hawaiian and minority-serving organizations, including community colleges, and this has led to a diverse cohort of undergraduate SOEST Scholars. However, for these students to persist on a STEM pathway and ultimately diversify the field of oceanography, developing research and other technical skills is not enough: they also need to develop self-efficacy.
Self-efficacy (a person’s belief that they can accomplish a given task or achieve a desired outcome) has been shown to be a key factor in successful academic performance that can help motivate students to persist in the face of adversity (Bandura, 1977; Multon et al., 1991; Zimmerman, 2000), including in the ocean and Earth sciences (Kortz et al., 2019) and across STEM fields (Andrew, 1998; Williams and George-Jackson, 2014). In some studies (Zusho et al., 2003), self-efficacy predicted student performance and persistence better than other cognitive variables, even when controlling for prior achievement (Lent et al., 1986). Studies of indigenous students have similarly shown significant, positive relationships between self-efficacy and academic success (Bryan, 2004; Frawley et al., 2017) and between self-efficacy and persistence (Gloria and Robinson Kurpius, 2001).
The motivation of this study is to see how student self-evaluations of their own skills and performances compare with their advisors’ evaluations. This analysis could potentially shed light on student self-efficacy. Further, this paper explores any potential differences between student vs. advisor assessments through a demographic lens, as prior research studies indicate that students from underrepresented groups—such as women (Hackett, 1985; Falk et al., 2016), Native Americans (Brown and Lavish, 2016), and other underrepresented minorities (Carpi et al., 2017)—tend to report lower self-efficacy. Thus, these results can inform how we train diverse undergraduate researchers in oceanography.
Data and Methods
Survey data were collected from 30 diverse undergraduates and their research advisors who participated in the SOEST Scholars Program in 2016–17 and 2017–18 (response rate of 83%). Figure 1 summarizes student demographics.
We collected two types of survey data, which we term “Absolute” and “Growth.” In the Absolute set, students and advisors evaluate the students’ skills and performances at the end of the research experience in 10 areas (e.g., amount of work accomplished, quality of work performed) along a five-point Likert scale ranging from Unsatisfactory to Excellent. In the Growth set, students and advisors evaluate the extent to which the students changed or grew over the course of the research experience in nine areas (e.g., works more independently, takes more initiative to problem-solve) along a five-point Likert scale ranging from Strongly Disagree to Strongly Agree. (Table 1)
Our null hypothesis is that there is no statistically significant difference between student vs. advisor assessments of students’ skills and performances, as measured by Absolute and Growth survey items. We test this hypothesis in two ways: (1) comparing the student vs. advisor responses to each individual survey item, and (2) comparing the student vs. advisor responses to each data set (Absolute and Growth) as a whole. For the former analysis, we perform a paired, two-tailed t-test. For the latter, we apply a non-parametric permutation test.
We then examined any differences in student-advisor ratings by gender, ethnicity, and the intersectionality of these identities. This analysis was motivated by previous studies that found that women and certain minority groups—and particularly students at the intersection of those identities—often report lower self-efficacy (see Introduction). For gender, we compared men vs. women, as none of the students reported a non-binary gender. For ethnicity, we compared Native Hawaiians and Pacific Islanders (NHPI) vs. non-indigenous students (non-NHPI); this choice was determined by the data set rather than a priori, as 50% of our students were NHPI. For the intersectionality analysis, we compared four categories: NHPI women, NHPI men, non-NHPI women, and non-NHPI men.
Further details on data and methods are provided in the online supplementary materials.
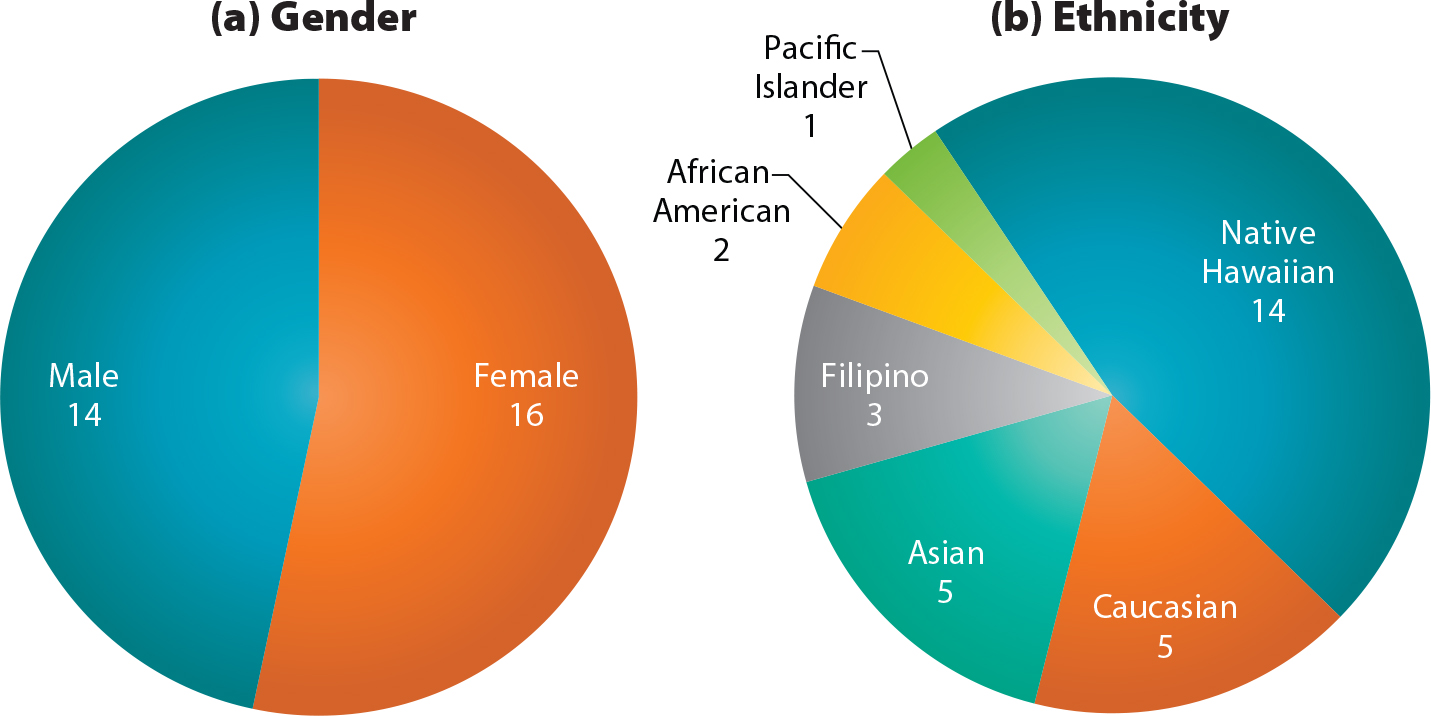
Figure 1. Gender and ethnicity demographics of 30 SOEST Scholars involved in the study described here. Half (15) are Native Hawaiians and Pacific Islanders (NHPI); the other half represent a range of non-indigenous identities. > High res figure
|
Table 1. Quantification of Likert responses to Absolute and Growth survey items on a scale of 1 to 5. > High res table

|
Results
Absolute Results (All Students and Advisors)
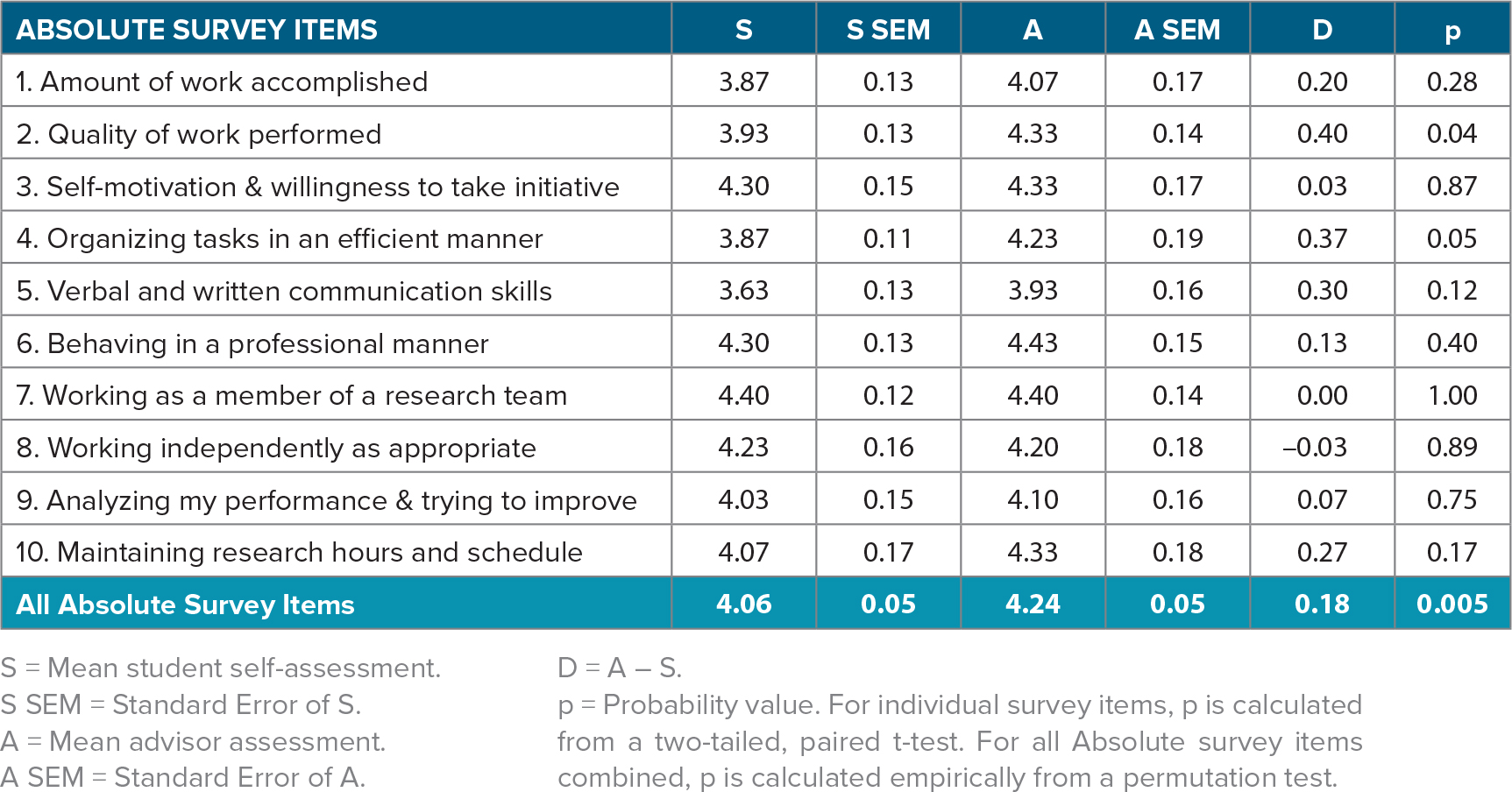
As a group, the 30 SOEST Scholars consistently underrated their Absolute skills and performances relative to their advisors’ ratings (Table 2 and Figure 2). For eight of 10 survey items, D values were positive, ranging from 0.03 to 0.40, indicating that the students’ mean self-ratings were lower than the advisors’ mean ratings. The remaining two items yielded D = 0 and D = –0.03, respectively indicating that the mean student self-rating was identical or very slightly higher than the mean advisor rating. T-test results for each survey item indicate that most of these student-advisor differences were not statistically significant (defined as p < 0.05): the only survey items found to have significant student-advisor differences were Quality of work performed (Absolute Item 2) and Organizing tasks in an efficient manner (Absolute Item 4).
Table 2. Comparison of advisor vs. student responses to 10 Absolute survey items assessing student skills and performances at the end of the undergraduate research experience. > High res table
|
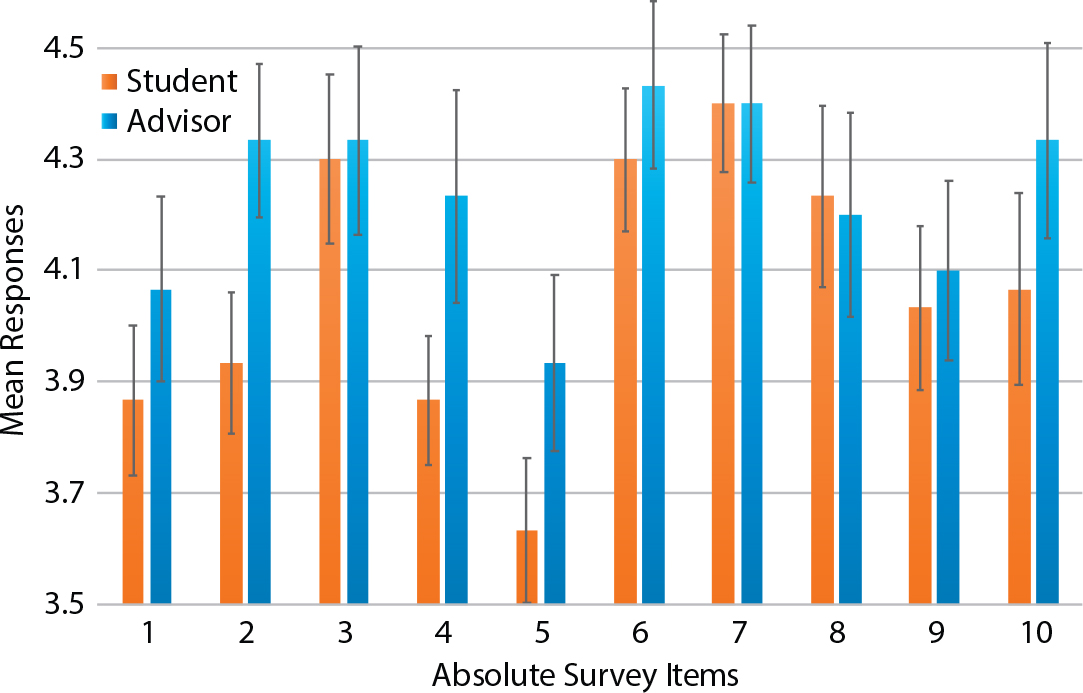
Figure 2. Histogram of student (orange) vs. advisor (blue) responses to Absolute survey items. Error bars represent ±1 one standard error of the mean. In eight of 10 survey items, the advisors rate the students more highly than the students rate themselves; however, most of these differences are not statistically significant. > High res figure
|
These data raise the question: Even though the advisor-student differences (D) for individual Absolute survey items are generally not statistically significant, does the general pattern of positive D values indicate that the students are statistically significantly underrating themselves relative to their advisors’ assessments on Absolute survey items as a whole? To answer this question, we performed a permutation test, and the answer is a resounding yes. We found p = 0.005, indicating that the advisor-student differences are highly significant (Figure 3 and last row of Table 2).
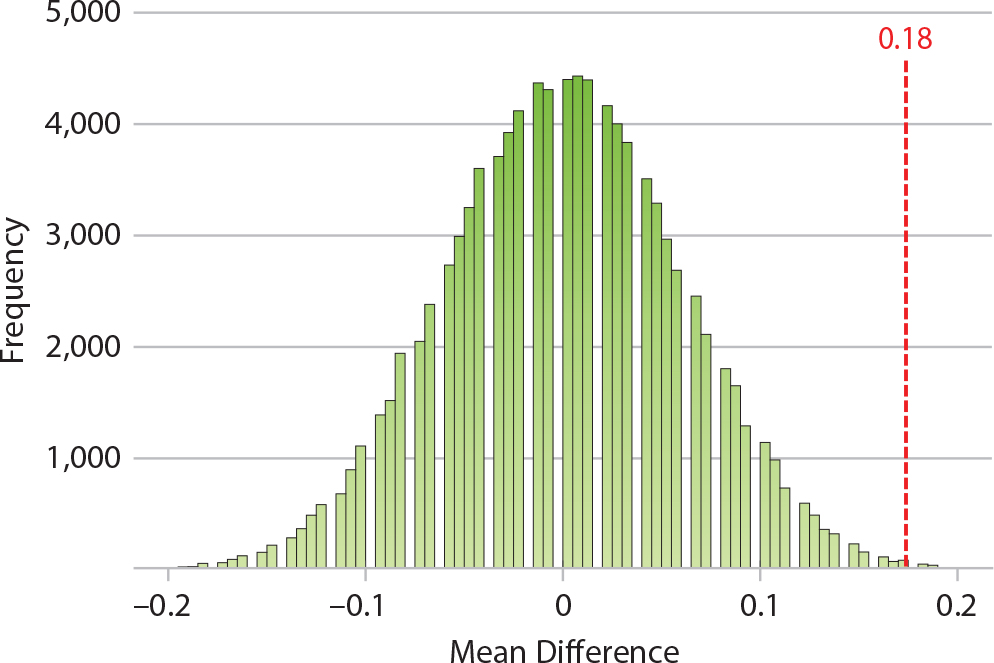
Figure 3. Distribution of permutation test results for the Absolute data set (10 survey items combined), showing highly significant student-advisor differences (observed mean difference = 0.18; p = 0.005). > High res figure
|
Growth Results (All Students and Advisors)
In contrast to the Absolute survey items, there is no systematic pattern of students’ underrating their Growth over the course of the research experience relative to their advisors’ ratings, let alone a statistically significant one (Table 3 and Figure 4). In fact, for six of the nine Growth items, students self-ranked their Growth higher than did their advisors (D < 0). Applying a paired, two-tailed t-test to each Growth survey item, none of these differences were statistically significant at α = 0.05 and only two p < 0.10 (p ranged from 0.06 to 0.75).
Table 3. Comparison of advisor vs. student responses to nine Growth survey items assessing growth during the undergraduate research experience. On the student survey, all Growth items begin with the phrase: “Compared to before I started the Scholars Program, I now…” On the advisor survey, the wording is “Compared to when s/he started the Scholars Program, the student now…” > High res table

|
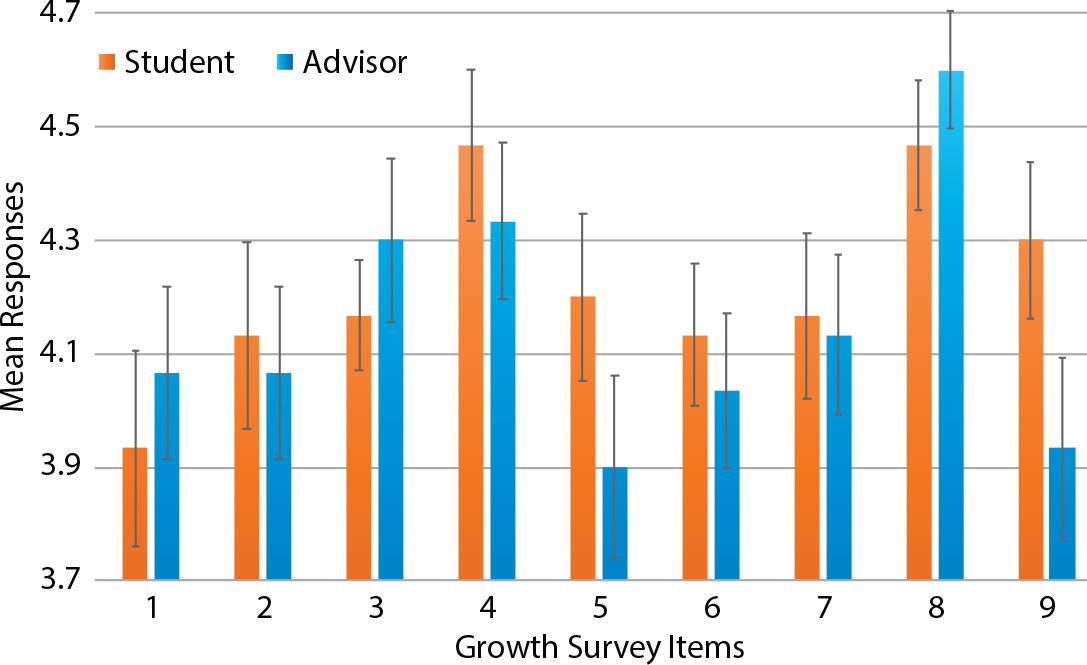
Figure 4. Histogram of student (orange) vs. advisor (blue) responses to Growth survey responses. Error bars represent ±1 one standard error of the mean. In contrast to the Absolute data, in six of nine Growth survey items, the advisors rate student growth lower than the students rate themselves, although these differences are generally not statistically significant. > High res figure
|
The two greatest—and most statistically significant—disparities between student vs. advisor mean ratings (both D < 0) pertained to the two survey items that concerned students’ future plans: Growth Item 5. Compared to before I started the program, I now am more interested in attending graduate school (D = –0.30; p = 0.06). Growth Item 9. Compared to before I started the program, I now am more interested in pursuing a STEM career (D = –0.37; p = 0.08). For both survey items, the students, on average, self-reported greater Growth during the course of the undergraduate research experience than did their advisors, resulting in D < 0.
Performing a permutation test on the complete Growth data set (all nine survey items combined) yielded p = 0.25. That is, 25% of the 100,000 permutations were tailward of the observed mean difference (–0.07; Figure 5). The low significance of this p-value is unsurprising, given the lack of systemic differences between the student vs. advisor responses to the Growth survey items (Figure 4).
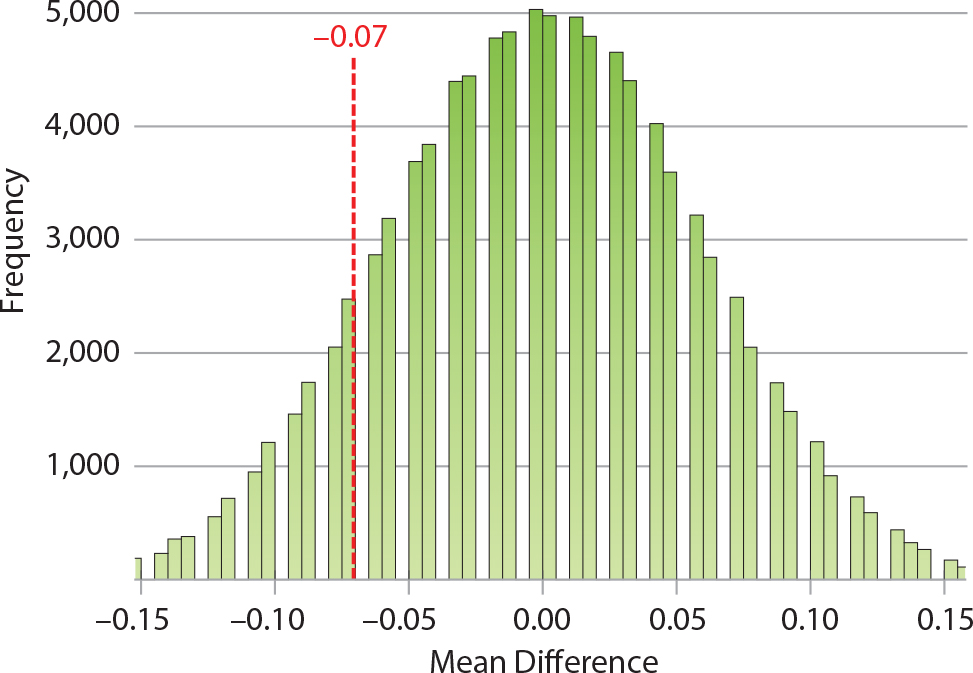
Figure 5. Distribution of permutation test results for the Growth data set (nine survey items combined), showing that the observed student-advisor differences are statistically insignificant (observed mean difference = –0.07; p = 0.25). > High res figure
|
Demographic Analyses
Here, we present the results of our demographic analyses by gender (men and women), ethnicity (NHPI and non-NHPI), and the intersection of gender and ethnicity (NHPI women, NHPI men, non-NHPI women, and non-NHPI men). For each analysis, we applied the permutation test methodology described above to the entire sets of Absolute and Growth survey items.
Gender
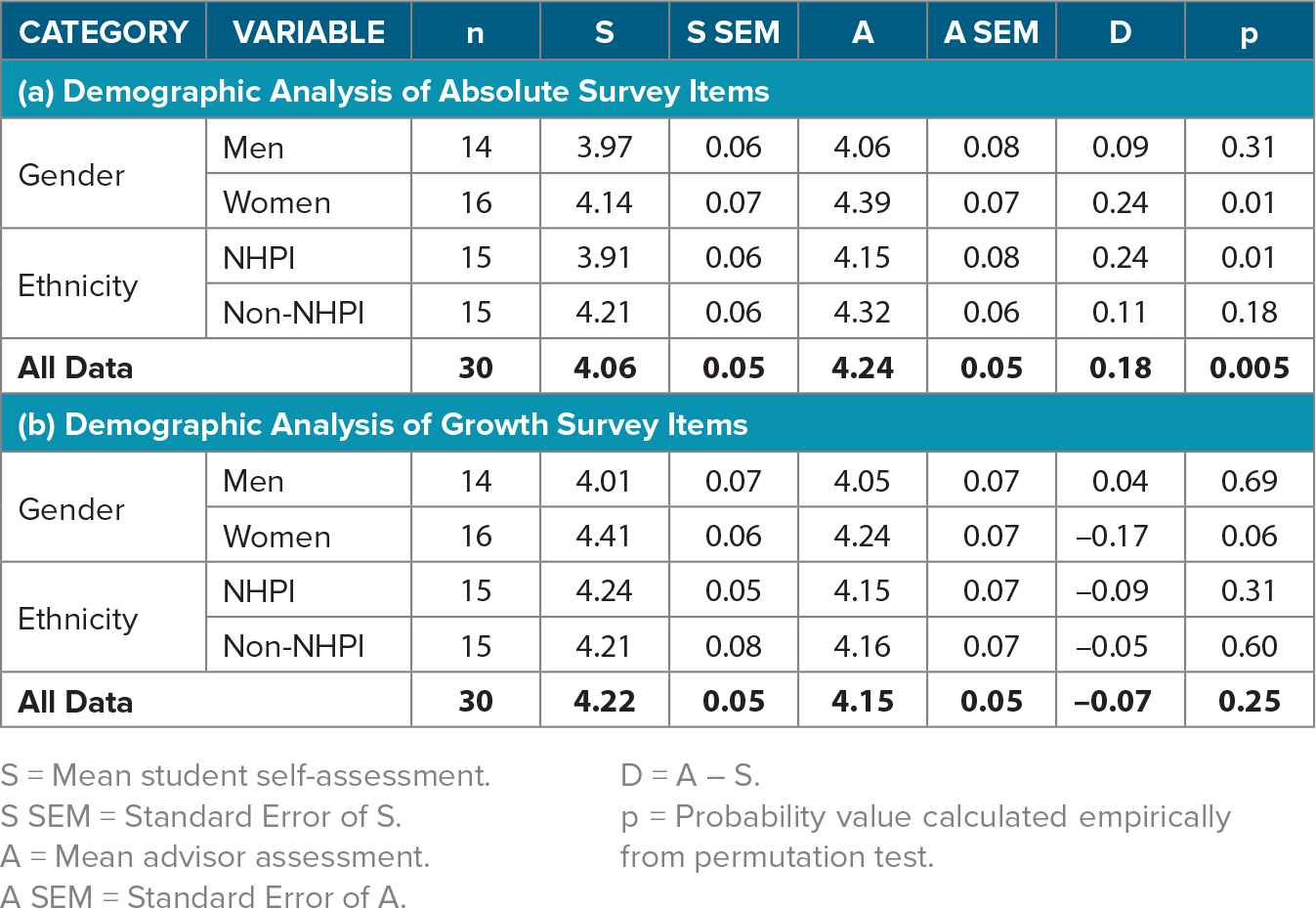
We found that both male (3.97) and female (4.14) students’ mean responses to Absolute survey items were lower than the corresponding advisors’ assessments (4.06 and 4.39, respectively). However, only the female students’ self-assessments were significantly less than their advisors’ assessments. The difference between ratings given by male students and their advisors on Absolute survey items was smaller in magnitude (D = 0.09 male vs. 0.24 female) and much less significant (p = 0.31 male vs. 0.01 female) (Table 4a).
For Growth survey items, the male students’ mean self-assessments (4.01) were again slightly lower but statistically indistinguishable (p = 0.69) from their advisors’ assessments (4.05). However, for female students, a different pattern emerged. The female students, as a group, self-rated their Growth more highly (4.41) than did their advisors (4.24), and this difference was reasonably significant (p = 0.06) (Table 4b).
Together, the Growth and Absolute permutation analyses indicate that female SOEST Scholars, on average, significantly underrated their skills and performances at the end of a research experience relative to their advisors’ assessments, but self-reported more Growth. In contrast, mean differences between male SOEST Scholars self-assessments vs. their advisors’ assessments were much smaller and within the range of error (not statistically significant).
Table 4. Comparison of advisor vs. student responses to (a) Absolute and (b) Growth survey items by gender (men and women) and ethnicity (NHPI and non-NHPI). No students reported other genders. > High res table
|
Ethnicity
We found that both NHPI (3.91) and non-NHPI (4.21) students’ mean responses to Absolute survey items were lower than the corresponding advisors’ assessments (4.15 and 4.32, respectively). However, only the NHPI students’ mean self-assessments were significantly less than their advisors’ mean assessments (p = 0.01). The difference between ratings given by non-NHPI students and their advisors on Absolute survey items was much less significant (p = 0.18) (Table 5a).
For Growth survey items, both NHPI (4.24) and non-NHPI (4.21) students’ mean self-assessments were slighter higher but statistically indistinguishable (p = 0.31 and 0.60, respectively) from their advisors’ assessments (4.15 and 4.16, respectively) (Table 5b).
Together, these results indicate that NHPI SOEST Scholars, on average, significantly underrate their skills and performances at the end of a research experience relative to their advisors’ assessments and report slightly (but not significantly) more Growth. Mean differences between non-NHPI SOEST Scholars vs. their advisors’ assessments for both Growth and Absolute survey items were small and not statistically significant.
Table 5. Comparison of advisor vs. student responses to (a) Absolute and (b) Growth survey items by gender (men and women) and ethnicity (NHPI and non-NHPI) through an intersectionality analysis. > High res table

|
Intersectionality
We explored the interplay between gender and ethnicity through an intersectionality analysis of four subgroups of students: NHPI women, NHPI men, non-NHPI women, and non-NHPI men. Although all subgroups, on average, underrated their Absolute skills relative to their advisors’ ratings (all D > 0), the magnitude and significance of the mean advisor-student difference varied greatly (Table 5a). NHPI women had the greatest (D = 0.36) and most significant (p = 0.02) underreporting of their Absolute skills and performances. Conversely, non-NHPI men had the smallest, least significant student-advisor difference (D = 0.09, p = 0.59). Assessments of Growth during the research experience were mixed, with all students except non-NHPI men self-reporting greater Growth than did their advisors, at greatly varying significant levels (0.04 to 0.63). Non-NHPI women reported the highest Growth (S = 4.31), the greatest disparity with their advisors’ ratings (D = –0.26), and the most significant differences (p = 0.04).Non-NHPI men were the only group of students to self-assess their mean Growth during the research experience as lower than did their advisors (D = 0.19, p = 0.13) (Table 5b).
Discussion and Recommendations
As a group, the SOEST Scholars significantly underrated their Absolute skills and performances relative to their advisors’ assessments (D = 0.18; p = 0.005). The advisor-student difference was most pronounced among NHPI women (D = 0.36; p = 0.02). As a group, the students were much more likely to rate themselves “very good” when their advisors rated them as “excellent” (Figure 6)—and this pattern was driven by the responses of NHPI women (Figure 7a) and NHPI men (Figure 7b). In this section, we explore possible interpretations of these results and their implications for training and assessing undergraduate researchers.

Figure 6. Line graph of Absolute survey responses (all students and advisors) showing that students’ underrating of their own research performances relative to their advisors’ assessments was largely due to students rating themselves “very good” in cases where their advisors rated them “excellent.” > High res figure
|
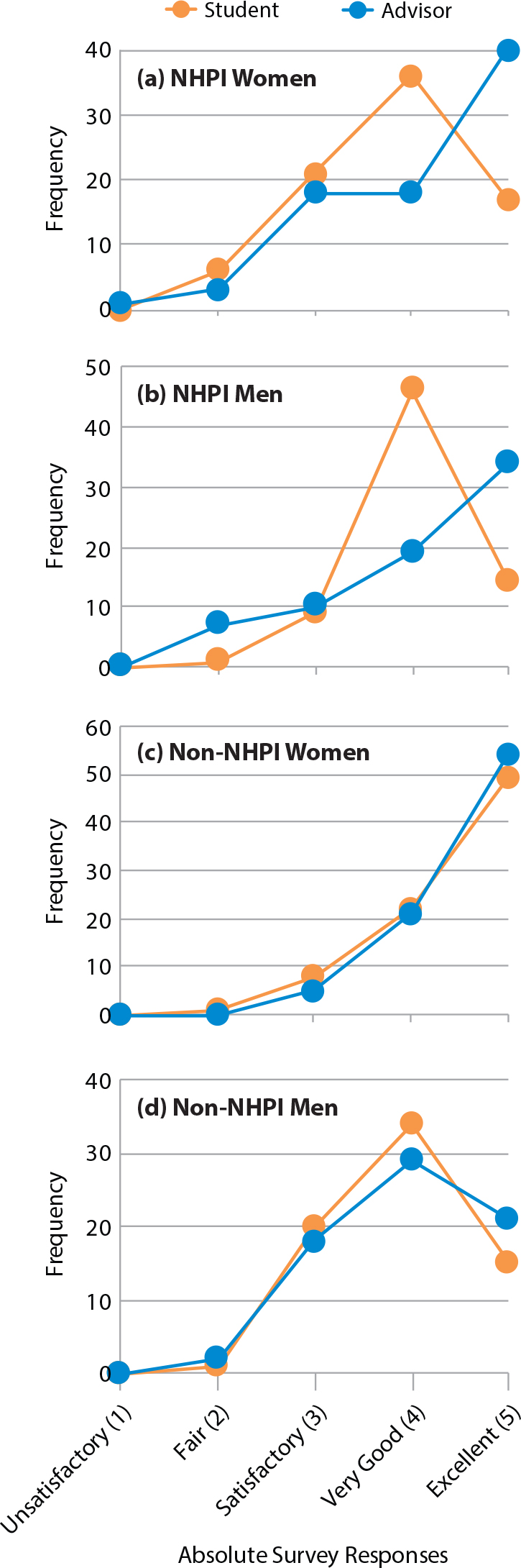
Figure 7. Line graphs of Absolute survey responses for (a) NHPI women, (b) NHPI men, (c) non-NHPI women, and (d) non-NHPI men. In many cases, NHPI students rated themselves “very good” in cases where their advisors rated them “excellent.” This pattern was not seen among non-NHPI students. > High res figure
|
Recommendation 1. Intentionally Focus on Building Student Self-Efficacy
One explanation for mean student Absolute survey responses being lower, on average, than mean advisor ratings could be low student self-efficacy. If true, this would suggest that the SOEST Scholars program, and perhaps undergraduate oceanography research programs in general, could be improved by intentionally focusing on building student self-efficacy, which has been linked to academic and career success. Here are a few examples of how this could be in done in the context of undergraduate research training in oceanography (based on Bandura, 1977, and Kortz et al., 2019).
- Design research projects (e.g., field and laboratory work) such that some degree of troubleshooting is required. Rather than handing students a perfected methodology, leave some issues for the students to encounter that are within their skill sets to solve. Developing mastery by overcoming progressively more difficult obstacles through perseverance and hard work is a highly effective way of building self-efficacy.
- Students also build self-efficacy through vicarious experiences: “If they can do it, I can too.” This is particularly effective when the person observed to be succeeding is of a similar background (e.g., gender, racial, or socioeconomic) to the student observer. For example, women mentoring women has been shown to significantly benefit women’s confidence, persistence, and performance in STEM (Bettinger and Long, 2005; Drury et al., 2011; Dawson et al., 2015; Thomas et al., 2015; Herrmann et al., 2016). It can sometimes be challenging, however, to find women, minority, and low-income role models and mentors in oceanography. Until the oceanography profession reflects our nation’s diversity, we recommend employing diverse near-peer mentors (e.g., graduate students) as well as professionals in other STEM fields (e.g., biology, engineering) to contribute relevant expertise.
- In addition to mastery and vicarious experiences, students build self-efficacy through social persuasion (e.g., being assured that success is possible) and reducing physical or emotional stress (e.g., through physical activity, positive environment; Bandura, 1977; Kortz et al., 2019). Service learning projects that address real-world needs (Astin et al., 2000; Eyler et al., 2001; Boyle et al., 2007; Celio et al., 2011), especially when combined with structured reflections (Conway and Amel, 2009) and outdoor activities (Stokes et al., 2015), invoke many of these strategies. Thus, incorporating these approaches into undergraduate research programs is highly recommended.
Recommendation 2. Design Evaluation Instruments to Avoid Use of Self-Promoting Language
A second, possibly related, interpretation for student Absolute survey responses being lower, on average, than the advisor ratings could be that students in general—and perhaps female and/or indigenous students in particular—may be less comfortable describing themselves or their research performances with self-promoting language. Lerchenmueller et al. (2019) found gender differences in how scientists present the importance of their research. Their textual analysis of over six million scientific research articles revealed that male-led research teams were 12% more likely to use glowing terms (e.g., “novel,” “unique,” “excellent”) to describe their research than female-led teams, and that such self-promotion was associated with greater numbers of citations. Kolev et al. (2019) similarly found gender differences in language use among scientists when communicating about their research. This is consistent with our findings that (particularly female NHPI) students are much more likely to rate themselves “very good” when their advisors rate them as “excellent.”
In contrast to the Absolute data, students’ mean ratings of their Growth over the undergraduate research experience exceeded their advisors’ ratings. One explanation for this disparity is that a different Likert Scale was used, this time ranging from Strongly Disagree to Strongly Agree. Perhaps students, on average, felt more comfortable Strongly Agreeing with a statement that they improved considerably in a given skill set over the course of a research experience, compared with saying they were Excellent at the end of the research experience. Thus, it could be valuable to reframe survey item language to enable use of a Likert Scale ranging from Strongly Disagree to Strongly Agree, rather than from Unsatisfactory to Excellent.
Recommendation 3. Discuss STEM Pathways and Careers at the End of the Research Experience
Interestingly, the two greatest—and most statistically significant—disparities between student vs. advisor mean ratings on Growth survey items pertained to the two survey items that concerned students’ future plans: Growth Item 5. Compared to before I started the program, I now am more interested in attending graduate school (D = –0.30; p = 0.06). Growth Item 9. Compared to before I started the program, I now am more interested in pursuing a STEM career (D = –0.37; p = 0.08). For both survey items, the students, on average, self-reported considerably more Growth than did their advisors (hence D < 0). This suggests that discussions and professional development on these topics may be more impactful if they are scheduled—or at least revisited—toward the end of the undergraduate research experience.
Limitations of This Study
Both the t-test and permutation analyses are based on quantification of the Likert scale responses to integers. A shortcoming of this approach is the inherent assumption of equal spacing between successive responses—for example, that the distance between “Strongly Disagree” and “Disagree” is the same as the distance between “Disagree” and “Not Sure.” For the t-test, this quantification is required. For the permutation test, it is possible to avoid this quantification by only considering the sign (not the magnitude) of the advisor-student difference. This sign-only approach would entail assigning one of three sign values to each student-advisor pair, –1 (S > A), 0 (S = A), and +1 (A > S), computing the mean, and comparing this observed mean value to that obtained from (say, 100,000) permutations of the original data set. However, doing so loses key information, thereby drastically reducing the power of the test. Therefore, we instead opted to quantify the Likert Scale and acknowledge this underlying assumption.
A second limitation of the study is rooted in the small size of our data set (30 student-advisor pairs) and the fact that SOEST Scholars represent numerous ethnicities. This combination precluded analysis of each individual ethnicity and limited our ethnicity analysis to comparing the responses of indigenous Native Hawaiian and Pacific Islander (NHPI) students with those of non-NHPI students. The latter category includes students from groups that have been traditionally underrepresented (e.g., African-American, Hispanic, Filipino) and overrepresented (e.g., Caucasian, Asian) in STEM fields. Therefore, caution is advised when interpreting these combined results.
Finally, we recognize that students and advisors have access to different information. For some Growth survey items (e.g., Question 3. Compared to before I started the program, I now am more confident about my STEM abilities), advisors may have little or no knowledge. Thus, we do not interpret student-advisor differences in responses to Growth survey items in terms of self-efficacy.
“Specifically, we recommend intentionally focusing on building student self-efficacy alongside technical training, designing evaluation instruments that avoid the use of self-promoting language, and scheduling—or at least revisiting—discussions on STEM pathways and careers toward the end of the undergraduate research experience.”
|
Conclusions
As a group, the undergraduate researchers consistently underrated their Absolute skills and performances relative to their advisors’ ratings. For all 10 Absolute survey items combined, the mean student and advisor ratings were 4.06 and 4.24, respectively—a difference that is highly significant (p = 0.005). Much of this advisor-student difference was driven by the responses of NHPI women (D = 0.36; p = 0.02). While men and non-indigenous students also rated themselves lower than did their advisors, the differences were considerably less (D: 0.09–0.12) as well as less significant (p: 0.18–0.59). NHPI students (both men and women) were much more likely to rate themselves “very good” when their advisors rated them as “excellent” than non-NHPI students. These differences in advisor-student ratings may be due to low student self-efficacy and/or discomfort in describing oneself with self-promoting language. The former explanation would lead to a recommendation to intentionally build student self-efficacy alongside technical training in undergraduate research programs, while the latter would suggest a need to reframe survey items to avoid the use of self-promoting language (e.g., using a Likert Scale ranging from Strongly Disagree to Strongly Agree, rather than from Unsatisfactory to Excellent). In contrast to the Absolute survey items, there was no statistically significant difference between student and advisor assessments on Growth survey items as a whole (p = 0.25).
However, for both Growth survey items pertaining to students’ interest in pursuing graduate school and STEM careers, the students self-reported greater mean Growth during the course of the undergraduate research experience than did their advisors (D = –0.30 and D = –0.37, respectively). This suggests that conversations with students about STEM pathways and careers should be held—or at least revisited—toward the end of the undergraduate research experience.
Acknowledgments
The SOEST Scholars program is supported by the National Science Foundation (NSF/OIA #1557349 and NSF/GEO #1565950) and Kamehameha Schools (KS#12662304). Maria Daniella Douglas and S. Anne Wallace contributed to the literature review. The authors thank two anonymous reviewers for input that improved this manuscript.

